A Little Bit About Me

Greetings! My name is Rahul Sharma. I am an Applied Scientist at Amazon within the Artificial General Intelligence organization, dedicated to advancing responsible AI for cutting-edge multimodal large language models. I have earned my Ph.D. from Ming Hsieh Institute of Electrical and Computer Engineering, University of Southern California where I worked with Prof. Shrikanth Narayanan at the interesection of technology and human behavior understanding.
My research interest lies in multimodal signal processing, more inclined towards the visual signal (Computer Vision), to understand human actions and behavior in multimedia content. Furthermore, I am keenly interested in semi-supervised systems and the notion of weeker-than-full supervision.
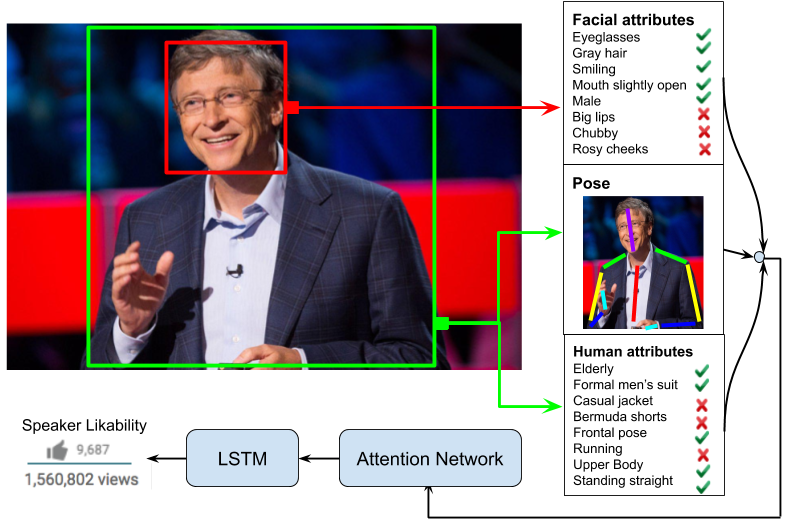
Immersed in the captivating field of multimodal technologies, my academic journey has been devoted to unraveling their profound impact on understanding human behavior. During my time at USC, I dedicated my efforts to crafting innovative strategies for detecting active speakers in long-form media videos, pushing the boundaries of Computational Media Intelligence. Prior to this, I honed my skills at the prestigious Indian Institute of Technology, Kanpur, earning both my Bachelors' and Masters' degrees in Electrical Engineering. My master's thesis delved into the fascinating world of public speaking videos, where I developed a computational framework to quantify a speaker's performance. This transformative experience was guided by the expertise of Dr. Tanya Guha and Dr. Gaurav Sharma.